
Dr. Pratyush Banerjee, Assistant Professor, School of HRM, XIMB
pratbanerjee@gmail.com

Abstract
This paper highlights the promise and scope of deep learning in the context of addressing one of the most burning issues in human resource management – predicting employee attrition. The study reviews key research papers in this area and tries to justify how much the practitioner community needs to update themselves to catch up with the latest developments in the field of machine and deep learning.
Introduction
Employee attrition is one of the major headaches for all organizations (Quinn et al., 2002). Attrition accounts for billions of dollars in terms of direct and indirect costs in the form of new hiring, lost productivity and opportunity costs (Sexton et al., 2004). In fact, the indirect or hidden costs of attrition account for 75-80 % of the total cost attributed due to attrition (Viswesvaran, 2003). Low turnover rates can help in ensuring over 50% more profit margins. As per the United States Department of Labor, hiring costs for new employees may be as high as one-third of new hire salary. This statistic is more alarming for middle and high-level vacancy filling (Sexton et al., 2004).
It has so far been a holy grail for HR managers to successfully identify the employees who are the potential leavers vis. a vis. those who are the likely stayers. However, thanks to rising in awareness in data analytics, HR practitioners have slowly begun developing a data-driven culture and have started adopting powerful predictive algorithms to predict attrition of potential churners (Alao and Adeyemo, 2013; Tamizharasi and UmaRani, 2014). HR Analytics has become a major game-changer in making HR decision-making more evidence-based (Lepak and Shaw, 2008). Davenport and colleagues (2010) have further added fuel to the debate that Analytics tools and techniques can help firms leverage several pressing HR issues such as talent retention and management.
When it comes to the application of machine learning in HR functions, a number of studies are also similarly limited in methods. Studies documenting such practices like application of decision trees (Alao and Adeyemo, 2013) and logistic regression (Somers, 1999; Quinn et al., 2002) to help managers predict important HR processes and outcomes including employee selection (Chien and Chen, 2008), employee performance (Al-Radaideh and Al Nagi, 2012) and attrition (Alao and Adeyemo, 2013) have not provided enough practitioner-focused materials so that these applications can become more mainstream in adoption.
From a practitioner’s perspective, some of the leading organizations in the world such as Google, IBM and Hewlett-Packard have successfully implemented predictive algorithms to identify potential churners and have taken preventive measures to restrict voluntary turnover of high-potential candidates (Rasmussen and Ulrich, 2015; Elkjaer and Filmer, 2015).
Antecedents of Employee Turnover: A Theoretical Perspective
Why do employees voluntarily quit organizations? Researchers have identified several macros and micro-organizational factors behind the phenomenon. Price (1977) defines turnover as ‘the ratio of a total number of organizational members who have left the firm during a particular period divided by an average number of people working at the firm during the same period. Past research has shed light on several antecedent factors behind employee attrition. For instance, Firth and colleagues (2004) have highlighted job-related stress, organizational commitment, and job dissatisfaction as major antecedents behind employees’ decision to quit. On the other hand, several researchers have argued that employee leaves their organizations primarily for monetary reasons (Griffeth et al., 2000). Toxic work environment (Abassi and Hollman, 2000) and organizational policies such as supervisory practices and communication transparency (Griffeth et al., 2012) have also been identified as major antecedents of voluntary attrition.
Researchers have developed several key theoretical frameworks for explaining the voluntary employee turnover process (Mobley et al., 1979). One early theory which explains why employees quit voluntarily is the ‘image theory’ (Beach, 1990), which posits that employees leave their organization after selectively analyzing certainly available decision heuristics. As per this theory, employees rarely have all the cues needed to decide whether to continue with their current employment. Even if most work-related factors are all right, individuals may decide to quit by concentrating on only a few negative aspects. Mobley (1977) developed one of the most widely cited and validated models describing the process of employee turnover. As per their model, employees first evaluate their level of satisfaction with their existing job and may either feel satisfied or dissatisfied with the same. If the latter is the case, then it triggers thoughts of quitting in the minds of the employees. Employees then start searching for alternatives and if they assess that the cost of quitting is not more than accepting the new opportunity, then they decide to quit. Later, Mobley, Griffeth, Hand and Meglino (1979) have expanded on their original model to include more distal antecedents such as adjustment issues of a spouse, organizational commitment, leadership perception and economic conditions of the labour market. The Mobley et al. model has received validation from several follow up studies and is considered as a benchmark work for conducting research on employee attrition (Lee et al., 2017). In this study, the author has referred to the extended model of Mobley and colleagues (1979) for identifying the variables/features to be captured/recorded in the historical dataset for predicting attrition.
HR Analytics: mainstream adoption scenario
The application of analytics in HR functions has been received with divided opinions from HR practitioners. The pioneering efforts of Jac Fitz-enz and Thomas Davenport to raise awareness about measuring the impact of HR processes on firm performance have gradually gained enthusiasm among the HR fraternity (Bassi, 2011; Davenport and Mittal, 2020).
However, there is also a serious concern among most HR practitioners that HR Analytics is only a passing fad. Falleta (2014), for instance, has conducted a survey to determine the use of HR Analytics across Fortune 1000 firms. His survey of 220 such firms suggests that only 15% of study respondents claimed HR Analytics played a central role in determining or implementing HR strategy. Lawler and Boudreau (2015) also report the results of a survey of over 100 Fortune 500 companies suggesting only about 30 per cent of these companies measure the relationship between HRM processes and their impact on financial and business outcomes. This was puzzling since over 70% of respondents of this survey reported using HR metrics to establish how efficient their HR processes are. Marler and Boudreau (2016) have provided a critical review of the state of adoption of HR Analytics. Their review identified 32 research papers published on the theme of HR Analytics in either peer-reviewed or practitioner-focused journals. The researchers excluded the practitioner-focused papers due to a lack of empirical rigour which reduced the number of relevant papers published on HR Analytics to 14. Out of these 14 papers, the empirical rigour was restricted to mostly illustrative descriptions or descriptive surveys with the only exception of Aral et al (2012) who conducted some predictive analytics testing the impact of HR Analytics on financial performance. Marler and Boudreau (2016) have cited a lack of studies demonstrating the actual application of analytics in HR.
Rasmussen and Ulrich (2015) posit a balanced argument to highlight why HR Analytics as a discipline has its sceptics and how it can manage to steer clear of such negative perceptions. They argue that the main hindrance in adopting HR Analytics rests at the top of the organization. If the management is on board, then the implementation of the applications gets more serious focus. This posits a very interesting context – can HR Analytics be actually effective in solving critical HR issues such as attrition and employee performance? Can machine learning be the key to unravelling these unsolved mysteries? In the next section, the author tries to build a case for this argument.
Machine Learning Algorithms in predicting voluntary attrition
Data analysts have argued on the supremacy of one predictive model over another (West et al., 1997; Olson et al., 2012). Predictive modelling techniques help in forecasting future actions of individuals through a supervised learning approach. Such techniques have been widely used in several spheres of management research including credit risk assessment (Olson et al., 2012), consumer buying behaviour (West et al., 1997) and off late in the area of human resource analytics (Sexton et al., 2004; Alao and Adeyemo, 2013; Tamizharasi and UmaRani, 2014).
Predictive analytics models can be clubbed under two broad categories – white-box models (eg: classification trees, linear models etc.) and black-box models (eg: artificial neural networks, random forests, XG Boost etc). For example, in one study, Saradhi and Palshikar (2011) developed predictive employee churn models through a case study where they compare different models such as Naïve Bayes, Support Vector Machines (SVM) and Random Forests to predict churn of current employees based on past employee data.
In terms of complexity, there are essentially two broad types of ML algorithms – white-box and black-box. White box models have the advantage of easy interpretation. For example, decision trees have been found to produce easily interpretable tree diagrams and they can function seamlessly even with missing values in data, while black-box models such as neural networks and random forests require the data to be complete in all aspects and researchers need to be wary of missing value issues (Zhang, 2007). Black-box models are extremely complex and interpretation from such models is not an easy task given what goes on in the hidden layer can never be observed (West et al., 1997; Zhang, 2007). The biggest advantage of black-box type machine learning algorithms lies in their error correction mechanism known as backpropagation (Garson, 1998), which helps the models to find the best possible prediction. Black-box algorithms also operate well with data distributed in a non-linear manner. In other words, black-box models are not restricted by the basic statistical assumptions of linearity and normal distribution, making these more robust for capturing complex volatile non-linear relationships (Somers, 1999).
Neural Networks and Deep Learning
Neural networks can compute multiple iterative solutions by splitting the overall sample into training, holdout and testing data and then choose the outcome which best describes the relationship between the independent variables and the outcome variable(s). A simple Neural Network comprises three basic components – an input layer, a hidden layer for data processing and an output layer (refer to figure 1).
The Multi-Layer Perceptron (MLP) is one of the most popular neural network architectures (Swingler, 1996; Somers, 1999). The MLP operates using the backpropagation technique of error minimization (Ripley, 2007). In backpropagation, the difference between predicted and actual outcomes is minimized iteratively by computing the observed error and then rectifying the weights of the input layer accordingly. Therefore, with each iterative learning cycle, individual cases are fed forward and the error is calculated and fed back to adjust the weights of the input layer in the model. This way, the final iteration renders a prediction that has higher accuracy compared to other similar statistical techniques such as logistic regression (Ripley, 2007).

Figure 1: Basic Neural Network Architecture (Source: Author)
Deep learning is the most complex machine learning algorithm (LeCun et al., 2015). This type of algorithm is best suited for analyzing uncertain and complex contexts. Here, the algorithm is faced with a game-like scenario. The computer employs trial and error to come up with a solution to the problem. To understand whether the trial and error are yielding the desired result, the artificial intelligence (AI) algorithm is guided through a carrot and stick approach where the algorithm is rewarded if it is doing a good job or receives penalties for poor performance (Alsheikh et al., 2016). The algorithm is programmed in such a way that its goal is to maximize the total reward. By conducting almost self-governed trials, reinforcement learning algorithms are capable of developing near-human and in some cases superhuman computing skills, In contrast to human beings, artificial intelligence can gather experience from thousands of parallel gameplays and thus have the advantage of unravelling unique solutions which human mind, despite all its brilliance, cannot process as effectively. A typical deep Neural Network is characterized by the presence of multiple hidden layers which can do parallel processing to analyze the data (refer to figure 2).
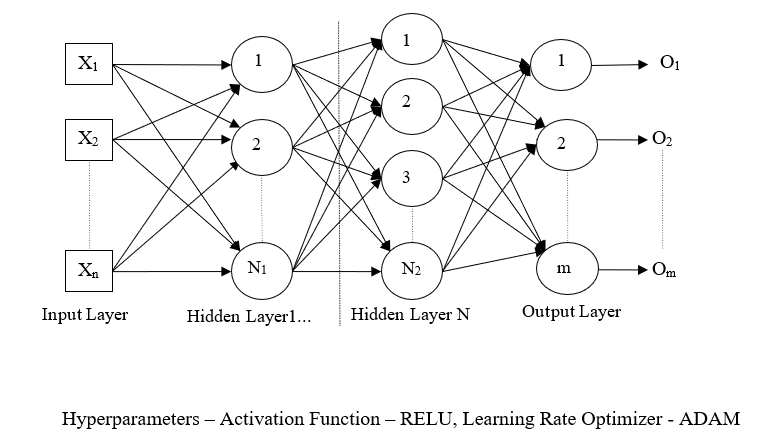
Figure 2: Deep Neural Network Architecture (Source: Author)
Deep machine learning techniques have been found to be more robust than a single machine learning algorithm due to the possibility of testing the model through multiple hidden layers (Somers, 1999; Quinn et al., 2002). In a study aimed at predicting caseworker attrition, Quinn and colleagues (2002) applied neural networks to their analysis and compared the prediction power of the former with a logistic regression analysis. The researchers split their sample of 385 child service caseworkers into training (273), validation (54) and testing (42) data. Results showed that the ANN algorithm outperformed the logistic regression model handsomely while predicting attrition, though the logistic regression fared slightly better in terms of predicting retention.
Previous research has highlighted the superior capability of deep ML algorithms in predicting the attrition of employees. For example, Somers (1999) used two different neural network paradigms – a multilayer perceptron (MLP) and a learning vector quantization (LVQ) model to predict voluntary employee turnover with 577 hospital employees. Out of these, 462 employees were chosen as training data and the remaining 115 employees were treated as holdout/test data. The MLP and the LVQ both predicted retention with 99 % accuracy, but in terms of predicting attrition, the LVQ (77%) outperformed the MLP (44% accuracy). A comparison with a logistic regression output showed that both the neural networks predicted with more accuracy than the logistic regression model.
In another interesting study, Sexton and his co-authors (2004) used a neural network trained using a modified genetic algorithm in their analysis of prediction of voluntary separation of employees working for a mid-sized firm. Historical data of employees who have worked in the organization for the past five years were obtained from the HR department. An analysis of 447 data points was conducted using a Neural Network Simultaneous Optimization Algorithm (NNSOA), a type of deep neural network. The NNSOA was found to have better predictive accuracy compared to a Discriminant analysis and other comparable backpropagation NN algorithms. In recent times, deep neural networks have been observed to achieve very high accuracy in predicting future business outcomes such as customer churn (Umayaparvathi and Iyakutti, 2017; Wang et al., 2019; de Caigny et al., 2020) and stock price prediction (Yu and Yan, 2020). Previous studies in the domain of HR Analytics have not applied complex ANN architecture such as Convolutional Neural Networks (CNNs) in predicting employee attrition. Sexton et al (2004) used a genetically trained neural network, but no researcher has explored the prediction potential of CNNs in the context of HR Analytics. There has also been scepticism about the use and effectiveness of deep learning with a small sample size (He et al., 2016; Levine et al., 2018). This issue has been countered recently by several researchers who have successfully demonstrated the impact of deep learning in prediction tasks with relatively small (n<1000) sample sizes (Keshari et al., 2020; Bornschein et al., 2020). Thus, it appears that the full potential of deep learning has not been utilized yet by practitioners and researchers alike.
Conclusion
Deep neural networks and other complex algorithms have the capability to help predict extremely chaotic data, and in near future, most firms will be using this approach for several critical analytic interventions such as attrition prediction, automating performance appraisals and resume screening processes. Already the early work in these areas has seen promising outcomes. The future seems to be full of exciting possibilities.
References
Abassi, S.M. & Hollman, K.W. (2000). Turnover: the real bottom line. Public Personnel
Management, 29, 333-342.
Al-Radaideh, Q. A., & Al Nagi, E. (2012). Using data mining techniques to build a classification model for predicting employee performance. International Journal of Advanced Computer Science and Applications, 3, 144-151.
Alsheikh, M. A., Niyato, D., Lin, S., Tan, H. P., & Han, Z. (2016). Mobile big data analytics using deep learning and Apache Spark. IEEE network, 30, 22-29.
Aral, S., Brynjolfsson, E., & Wu, L. (2012). Three-way complementarities: Performance Pay,
human resource analytics, and information technology. Management Science, 58, 913–931.
Barz, B., & Denzler, J. (2020). Deep learning on small datasets without pre-training using cosine loss, In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (pp. 1371-1380).
Bassi, L. (2011). Raging debates in HR Analytics. People and Strategy, 34, 14-18.
Beach, L.R. (1990). Image Theory: Decision Making in Personal and Organizational Contexts, Wiley, Chichester pp. 3-10.
Bornschein, J., Visin, F., & Osindero, S. (2020). November. Small data, big decisions: Model selection in the small-data regime. In International Conference on Machine Learning (pp. 1035-1044). PMLR.
Chien, C. F., & Chen, L. F. (2008). Data mining to improve personnel selection and enhance human capital: A case study in high-technology industry. Expert Systems with applications, 34, 280-290.
Cotter, A., Jiang, H., Gupta, M. R., Wang, S., Narayan, T., You, S., & Sridharan, K. (2019). Optimization with Non-Differentiable Constraints with Applications to Fairness, Recall, Churn, and Other Goals. Journal of Machine Learning Research, 20, 1-59.
Davenport, T. H., Harris, J., & Shapiro, J. (2010). Competing on talent analytics. Harvard Business Review, October 20, pp. 52-58.
Davenport, T. & Mittal, N. (2020). How CEOs can lead a data-driven culture. Harvard Business Review, March 23, retrieved from: https://hbr.org/2020/03/how-ceos-can-lead-a-data-driven-culture
De Caigny, A., Coussement, K., De Bock, K. W., & Lessmann, S. (2020). Incorporating textual information in customer churn prediction models based on a convolutional neural network. International Journal of Forecasting, 36, 1563-1578.
Deloitte India Workforce and Increment Trends Survey (2020). Retrieved from: https://www2.deloitte.com/content/dam/Deloitte/in/Documents/strategy/in-consulting-workforce-and-increment-trends-survey-noexp.pdf (accessed on May 29, 2021)
Draz, U., Jahanzaib, M., & Asghar, G. (2016). Identification of Determinants for Globalization of SMEs using Multi-Layer Perceptron Neural Networks. Mehran University Research Journal of Engineering and Technology, 35, 39-52.
Elkjaer, D., & Filmer, S. (2015). Trends and drivers of workforce turnover: the results from Mercer’s 2014 Turnover survey and dealing with unwanted attrition. Retrieved from: https://www.mercer.com/content/dam/mercer/attachments/global/webcasts/trends-and-drivers-of-workforce-turnover-results-from-mercers-2014-turnover-survey.pdf (accessed on: 12.12.2019)
Firth L, David J Mellor, Kathleen A Moore, & Claude Loquet (2007). How can managers reduce employee intention to quit? Journal of Managerial Psychology, 19, 170-187.
Garson, G. D. (1998), Neural networks: An introductory guide for social scientists, Thousand Oaks, CA: Sage.
Gonzalez, M. F., Capman, J. F., Oswald, F. L., Theys, E. R., & Tomczak, D. L. (2019). Where’s the IO? Artificial intelligence and machine learning in talent management systems. Personnel Assessment and Decisions, 5, 33-44.
Griffeth, R.W., Hom, P.W., & Gaertner, S (2000). A meta-analysis of antecedents and correlates of employee turnover: update, moderator tests, and research implications for the next millennium. Journal of Management, 26, 463-88.
Griffeth, R. W., Lee, T. W., Mitchell, T. R., & Hom, P. W. (2012). Further clarification on the Hom, Mitchell, Lee, and Griffeth (2012) model: Reply to Bergman, Payne, and Boswell (2012) and Maertz (2012). Psychological Bulletin, 138, 871–875.
Hampton, R., Dubinsky, A. J., & Skinner, S. J. (1986). A model of sales supervisor leadership behaviour and retail salespeople’s job-related outcomes. Journal of the Academy of Marketing Science, 14, 33-43.
Harris, J. G., Craig, E., & Light, D. A. (2011). Talent and analytics: New approaches, higher ROI. Journal of Business Strategy, 32, 4–13.
Keshari, R., Ghosh, S., Chhabra, S. Vatsa, M. & Singh, R. (2020). Unravelling Small Sample Size Problems in the Deep Learning World. IEEE Sixth International Conference on Multimedia Big Data (BigMM), 134-143.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521, 436-444.
Lee, T. W., Hom, P. W., Eberly, M. B., Junchao (Jason) Li, & Mitchell, T. R. (2017). In the next decade of research in voluntary employee turnover. Academy of management perspectives, 31, 201-221.
Lepak, D. P., & Shaw, J. D. (2008). Strategic HRM in North America: Looking to the future.
The International Journal of Human Resource Management, 19, 1486–1499.
Marler, J. H. & Boudreau, J. W. (2017). An evidence-based review of HR Analytics. The International Journal of Human Resource Management,28, 3-26.
Mathan, K., Kumar, P. M., Panchatcharam, P., Manogaran, G., & Varadharajan, R. (2018). A novel Gini index decision tree data mining method with neural network classifiers for prediction of heart disease. Design Automation for Embedded Systems, 22, 225-242.
Mobley, W. (1977). Intermediate linkages in the relationship between job satisfaction and
employee turnover. Journal of Applied Psychology, 62, 237-240.
Mobley, W., Griffeth, R., Hand, H., & Meglino, B. (1979). Review and conceptual analysis
of the employee turnover process. Psychological Bulletin, 86, 493-522.
Mondore, S., Douthitt, S., & Carson, M. (2011). Maximizing the Impact and Effectiveness of HR Analytics to Drive Business Outcomes. People and Strategy, 34, 20-27.
Olson, D. L., Delen, D., & Meng, Y. (2012). Comparative analysis of data mining methods for bankruptcy prediction. Decision Support Systems, 52, 464-473.
Price, J.L (1977). The study of turnover. 1st edition, Iowa State University Press, IA, pp10-25.
Quinn, A., Rycraft, J. R., & Schoech, D. (2002). Building a model to predict caseworker and supervisor turnover using a neural network and logistic regression. Journal of Technology in Human Services, 19, 65-85.
Ripley, B. D. (2007). Pattern recognition and neural networks, Cambridge University Press.
Saradhi, V. V., & Palshikar, G. K. (2011). Employee churn prediction. Expert Systems with Applications, 38, 1999-2006.
Sexton, R. S., McMurtrey, S., Michalopoulos, J. O. & Smith, A. M. (2005). Employee turnover: a neural network solution. Computers and Operations Research, 32, 2635-2651.
Somers, M. J. (1999). Application of two neural network paradigms to the study of voluntary employee turnover. Journal of Applied Psychology, 84, 177-185.
Swingler, K. (1996). Applying neural networks: a practical guide. Morgan Kaufmann.
Tamizharasi, K., & Rani, U. (2014). Employee Turnover Analysis with Application of Data Mining Methods. International Journal of Computer Science and Information Technologies, 5, 562-566.
Umayaparvathi, V., & Iyakutti, K. (2017). Automated feature selection and churn prediction using deep learning models. International Research Journal of Engineering and Technology, 4, 1846-1854.
West, P. M., Brockett, P. L. & Golden, L. L. (1997). A comparative analysis of neural networks and statistical methods for predicting consumer choice. Marketing Science, 16, 370-391.
Viswesvaran, C. (2003). Introduction to special issue: Role of technology in shaping the future of staffing and assessment. International Journal of Selection and Assessment, 11,
107–111.
Yu, P., & Yan, X. (2020). Stock price prediction based on deep neural networks. Neural Computing and Applications, 32, 1609-1628.
Zhang, G. P. (2007). Avoiding pitfalls in neural network research. IEEE Transactions on Systems, Man, and Cybernetics
Posted in HR Technology | No Comments »
View Next Articles

Recent Articles
- The Communication Network: Public Relations in the Digital Era
- Machines Are Learning, How About You?
- Positioning Exponential Technology – Leveraging for Effective Industrial Relations
- HR Analytics – Enabler for Strategic Business Partnership
- Machine Learning applications in the domain of HR Analytics
- Pandemic provided the tailwind to HR technology sector
- Gamification using Digital Twin for Leadership Management
- HR Tech-Options to evaluate
- Metaverse & Future Workplace
- Beat Burnout by investing in HR Technology and Automation
- How to Harness the Power of AI in HRM
- Driving innovation & Experimentation through Digital HR Transformation & Building Employee Experience
- HR Tech Trends
- Decoding the ‘Digital Personal Data Protection Bill 2022’